
2017年的双十一圆满结束了,1682亿的成交额再一次刷新了记录,而HSF(High Speed Framework,分布式服务框架)当天调用量也突破了3.5万亿次,调用量是2016年双十一的三倍多。为了这不平凡的一天中,HSF经历了一年多的磨练,从架构升级到性能优化,从可用性提升到运维提升,完成了从2.1到2.2的全面升级,截止到双十一开始的一刻,HSF2.2在全网机器占比超过75%,并成功接受了大促考验。
从HSF2.1到HSF2.2的目标是提升HSF框架的扩展性、易用性和性能,相当于将原有HSF推倒了重新来过,因此涉及到的内容众多,这里不做展开,我们仅从架构升级、性能优化和运维提升三个方面来聊一下HSF2.2做了什么,有什么能帮到大家,以及如何解决了双十一的一些问题。

架构升级
HSF2.1主要被用户抱怨的一点就是扩展性不强,比如:不少用户想拦截调用请求但无法方便做到,只好退而求其次,使用代理来包装HSF的客户端或者服务端,这样做一来显得繁琐,二来出现问题不易排查。不光是用户的扩展支持的不好,框架自身对不同的开源组件适配也显得力不从心,比如:支持ZooKeeper作为注册中心的方案一直难以实施,原因在于框架内部与ConfigServer耦合过于紧密。无论是用户还是框架的维护者,都受限于现有架构,这是HSF需要改变的地方。
HSF2.2的架构与原有版本有了显著变化,首先是层与层之间的边界清晰,其次组件之间的关系职责明确,最后是扩展可替换的思想贯穿其中,下面我们先看一下新的架构:

可以看到HSF2.2从宏观上分为了三个域:框架、应用和服务,其中框架是对上层多个应用做支撑的基础,而服务属于具体的某个应用,从这种划分可以看出,HSF2.2是天然支持多应用(或多模块)部署的。每个域中,都有各自的功能组件,比如:服务域中的InvocationHandler就是对服务调用逻辑的抽象,通过扩展其中的ClientFilter或者ServerFilter完成对客户端或者服务端的调用处理工作,这里只是罗列了主要的功能组件和扩展点,以下是对它们的说明:
服务 ,对应于一个接口,它可以提供服务或者消费服务
| 组件名 | 扩展点 | 说明 |
|---|---|---|
| InvocationHandler | ClientFilter | 客户端调用拦截器,扩展它实现调用端的请求拦截处理 |
| InvocationHandler | ServerFilter | 服务端调用拦截器,扩展它实现服务端的请求拦截处理 |
| Router | AbstractMultiTargetRouter | 客户端调用多节点选择路由器,扩展它实现客户端调用多节点的路由 |
| Router | AbstractSingleTargetRouter | 客户端调用单节点选择路由器,扩展它实现客户端调用单节点的路由 |
应用 ,对应于一个应用或者一个模块,它管理着一组消费或者发布的服务
| 组件名 | 扩展点 | 说明 |
|---|---|---|
| Registry | AddressListener | 注册中心地址监听器,扩展它可以获取到注册中心推送的地址列表 |
| Registry | AddressListenerInteceptor | 注册中心地址拦截器,扩展它可以监听到注册中心推送地址并加以控制 |
| Protocol | ProtocolInterceptor | 订阅发布流程,扩展它可以捕获应用发布或者消费的具体服务 |
框架 , 对应于框架底层支持,它统一管理着线程、链接等资源
| 组件名 | 扩展点 | 说明 |
|---|---|---|
| Serialize | Serializer | 序列化和反序列化器,需要实现新的序列化方式可以扩展它 |
| Packet | PacketFactory | 协议工厂, 适配不同的RPC框架协议需要扩展它 |
| Stream | StreamLifecycleListener | 长连接生命周期管理监听器,扩展它可以监听到长连接的建立和销毁等生命周期 |
| Stream | StreamMessageListener | 长连接事件监听器,扩展它可以监听到每条连接上跑的数据 |
分类介绍了HSF2.2的主要组件后,我们来看看架构的改变,扩展性的提升,能够为业务方,为他们更好的支持双十一带来什么。
纯异步调用拦截器
HSF异步future调用被业务方越来越多的使用,但是eagleeye对future调用的耗时统计上一直不准,因为future调用返回的是默认值,所以业务看到的是一次飞快的调用返回,它真实的耗时该如何度量?信息平台承载了集团的众多内部服务业务,一直苦于没有办法全面的监控HSF的调用记录,也无法做到异常报警,难道还要让所有的使用方配置代理?
HSF2.2设计的InvocationHandler组件以及扩展,完美的解决了这个问题,我们近距离观察一下InvocationHandler以及其扩展,以客户端调用场景为例:一次调用是如何穿过用户扩展的调用拦截器的。
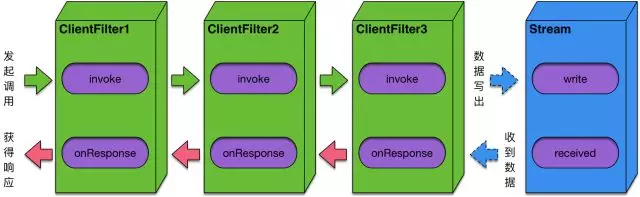
可以看到,HSF2.2定义的调用拦截器不是一个简单的正向invoke过程,它还具备响应回来时的逆向onResponse过程,这样一来一回很好的诠释了HSF同步调用异步执行的调用模型。用户可以通过在一次调用中计算invoke和onResponse之间的时差来获得调用的正确耗时,而不用关心HSF调用是同步还是异步,用户也可以扩展一个调用拦截器穿插在其中,用于监控HSF的调用内容,而不用让应用方做任何代码上的改造。
多应用支持
多模块部署一直是业务方同学探索的热点,从合并部署开始,HSF就有限的支持了多应用部署,但是一直没有将其融入到架构中。在HSF2.2中,应用不仅仅是作为托管服务的容器而是成为核心领域,多应用序列化的难题,就在应用层解决。
(模块在HSF2.2中也会被认为是一个应用,以下提到模块或者应用可以认为是一个概念。)
HSF2.2支持多个应用部署的结构如下图所示:
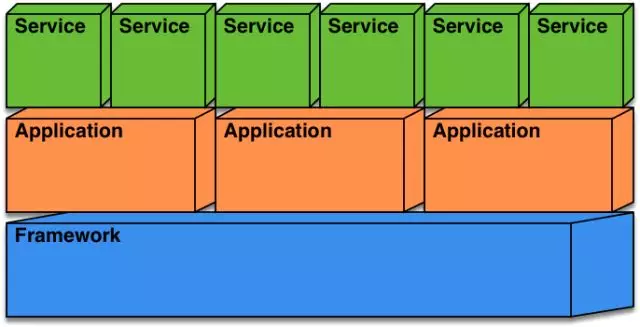
可以看到,HSF2.2框架域处于最底层,它向上为应用提供了线程、连接等多种资源的支持,而应用能够发布或者订阅多个服务,这些服务能够被应用统一管理,也支持更加精细化的配置,层与层的司职明确让HSF具有了良好的适应性。
性能优化
RPC流程中,序列化是开销很大的环节。尤其现在业务对象都很复杂,序列化开销更不容小觑。
下面先介绍下今年HSF针对Hessian的几个优化点。
优化1:元数据共享
hessian序列化会将两种信息写到输出流:
元数据:即类全名,字段名
值数据:即各个字段对应值(如果字段是复杂类型,则会递归传递该复杂类型的元数据和内部字段的值数据)
在hessian1协议里,每次写出Class A的实例时,都会写出Class A的元数据和值数据,就是会重复传输相同的元数据。针对这点,hessian2协议做了一个优化就是:在“同一次序列化上下文”里,如果存在Class A的多个实例,只会对Class A的元数据传输一次。该元数据会在对端被缓存起来重复使用,下次再序列化Class A的对象时,只需要先写出对元数据的一个引用句柄(缓存中的index,用一个int表示),然后直接写出值数据即可。接受方通过元数据句柄即可知道后面的值数据对应的类型。
这是一个极大的提升。因为编码字段名字(就是字符串)所需的字节数很可能比它对应的值(可能只是一个byte)更多。
不过在官方的hessian里,这个优化有两个限制:
序列化过程中类型对应的Class结构不能改变
元数据引用只能在“同一个序列化上下文”,这里的“上下文”就是指同一个HessianOutput和HessianInput。因为元数据的id分配和缓存分别是在HessianOutput和HessianInput里进行的
限制1我们可以接受,一般DO不会再运行时改变。但是限制2不太友好,因为针对每次请求的序列化和反序列化,HSF都需要使用全新构造的HessianOutput和HessianInput。这就导致每次请求都需要重新发送上次请求已经发送过的元数据。
针对限制2,HSF实现了跨请求元数据共享,这样只要发送过一次元数据,以后就再也不用发送了,进一步减少传输的数据量。实现机制如下:
修改hessian代码,将元数据id分配和缓存的数据结构从HessianOutput和HessianInput剥离出来。
修改HSF代码,将上述剥离出来的数据结构作为连接级别的上下文保存起来。
每次构造HessianOutput和HessianInput时将其作为参数传入。这样就达了跨请求复用元数据的目的。
该优化的效果取决于业务对象中,元数据所占的比例,如果“精心”构造对象,使得元数据所占比例很大,那么测试表现会很好,不过这没有意义。我们还是选取线上核心应用的真实业务对象来测试。从线上tcp dump了一个真实业务对象,测试同学以此编写测试用例得到测试数据如下:
新版本比老版本CPU利用率下降10%左右
新版本的网络流量相比老版本减少约17%
线上核心应用压测结果显示数据流量下降一般在15%~20%之间。
优化2:UTF8解码优化
hessian传输的字符串都是utf8编码的,反序列化时需要进行解码。
hessian现行的解码方式是逐个字符进行。代码如下:
private int parseUTF8Char() throws IOException { int ch = _offset < _length ? (_buffer[_offset++] & 0xff) : read();
if (ch < 0x80)
return ch;
else if ((ch & 0xe0) == 0xc0) {
int ch1 = read();
int v = ((ch & 0x1f) << 6) + (ch1 & 0x3f); return v;
} else if ((ch & 0xf0) == 0xe0) {
int ch1 = read();
int ch2 = read();
int v = ((ch & 0x0f) << 12) + ((ch1 & 0x3f) << 6) + (ch2 & 0x3f);
return v;
} else
throw error("bad utf-8 encoding at " + codeName(ch));
}UTF8是变长编码,有三种格式:
1 byte format: 0xxxxxxx
2 byte format: 110xxxxx 10xxxxxx
3 byte format: 1110xxxx 10xxxxxx 10xxxxxx
上面的代码是对每个字节,通过位运算判断属于哪一种格式,然后分别解析。
优化方式是:通过unsafe将8个字节作为一个long读取,然后通过一次位运算判断这8个字节是否都是“1 byte format”,如果是(很大概率是,因为常用的ASCII都是“1 byte format”),则可以将8个字节直接解码返回。以前8次位运算,现在只需要一次了。如果判断失败,则按老的方式,逐个字节进行解码。主要代码如下:
private boolean parseUTF8Char_improved() throws IOException {
while (_chunkLength > 0) {
if (_offset >= _length && !readBuffer()) {
return false;
}
int sizeOfBufferedBytes = _length - _offset; int toRead = sizeOfBufferedBytes <= _chunkLength ? sizeOfBufferedBytes : _chunkLength;
// fast path for ASCII
int numLongs = toRead >> 3;
for (int i = 0; i < numLongs; i++) {
long currentOffset = baseOffset + _offset; long test = unsafe.getLong(_buffer, currentOffset);
if ((test & 0x8080808080808080L) == 0L) { _chunkLength -= 8;
toRead -= 8;
for (int j = 0; j < 8; j++) { _sbuf.append((char)(_buffer[_offset++])); }
} else {
break;
}
}
for (int i = 0; i < toRead; i++) { _chunkLength--;
int ch = (_buffer[_offset++] & 0xff);
if (ch < 0x80) { _sbuf.append((char)ch);
} else if ((ch & 0xe0) == 0xc0) {
int ch1 = read();
int v = ((ch & 0x1f) << 6) + (ch1 & 0x3f);
_sbuf.append((char)v);
} else if ((ch & 0xf0) == 0xe0) {
int ch1 = read();
int ch2 = read();
int v = ((ch & 0x0f) << 12) + ((ch1 & 0x3f) << 6) + (ch2 & 0x3f);
_sbuf.append((char)v);
} else
throw error("bad utf-8 encoding at " + codeName(ch));
}
}
return true;
}同样使用线上dump的业务对象进行对比,测试结果显示该优化带来了 17% 的性能提升:
time: 981
improved utf8 decode time: 810
(981-810)/981 = 0.1743119266055046
优化3:异常流程改进
hessian在一些异常场景下,虽然业务不一定报错,但是性能却很差。今年我们针对两个异常场景做了优化。
UnmodifiableSet构造异常
某核心应用压测发现大量如下错误:
java.util.Collections$UnmodifiableSet
========================================================================================
java.lang.Throwable.
java.lang.Exception.
java.lang.ReflectiveOperationException.
java.lang.InstantiationException.
java.lang.Class.newInstance(Class.java:427)
com.taobao.hsf.com.caucho.hessian.io.CollectionDeserializer.createList(CollectionDeserializer.java:107)
com.taobao.hsf.com.caucho.hessian.io.CollectionDeserializer.readLengthList(CollectionDeserializer.java:88)
com.taobao.hsf.com.caucho.hessian.io.Hessian2Input.readObject(Hessian2Input.java:1731)
com.taobao.hsf.com.caucho.hessian.io.UnsafeDeserializer$ObjectFieldDeserializer.deserialize(UnsafeDeserializer.java:387)
这是Hessian对UnmodifiableSet反序列化的一个问题,因为UnmodifiableSet没有默认构造函数,所以Class.newInstance会抛出,出错之后Hessian会使用HashSet进行反序列化,所以业务不会报错,但是应用同学反馈每次都处理异常,对性能影响比较大。
另外Collections$UnmodifiableCollection,Collections$UnmodifiableList, Collections$UnmodifiableMap, Arrays$ArrayList也有一样的问题。
针对这些构造函数一定会出错的类型,我们修改了Hessian的代码直接跳过构造函数的逻辑,较少不必要的开销。
重复加载缺失类型
某核心应用压测发现大量线程block在ClassLoader.loadClass方法
"HSFBizProcessor-DEFAULT-7-thread-1107" #3049 daemon prio=10 os_prio=0 tid=0x00007fd127cad000 nid=0xc29 waiting for monitor entry [0x00007fd0da2c9000] java.lang.Thread.State: BLOCKED (on object monitor) at com.taobao.pandora.boot.loader.LaunchedURLClassLoader.loadClass(LaunchedURLClassLoader.java:133) - waiting to lock <0x0000000741ec9870> (a java.lang.Object) atjava.lang.ClassLoader.loadClass(ClassLoader.java:380) at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:348) at com.taobao.hsf.com.caucho.hessian.io.SerializerFactory.getDeserializer(SerializerFactory.java:681)
排查确认是业务二方包升级,服务端客户端二方包版本不一致,导致老版本的一边反复尝试加载对应的新增类型。虽然该问题并没有导致业务错误,但是确严重影响了性能,按应用同学的反馈,如果每次都尝试加载缺失类型,性能会下降一倍。
针对这种情况,修改hessian代码,将确认加载不到的类型缓存起来,以后就不再尝试加载了。
优化4: map操作数组化
大型系统里多个模块间经常通过Map来交互信息,互相只需要耦合String类型的key。常见代码如下:
public static final String key = "mykey"; Map<String,Object> attributeMap = new HashMap<String,Object>(); Object value = attributeMap.get(key);
大量的Map操作也是性能的一大消耗点。HSF今年尝试将Map操作进行了优化,改进为数组操作,避免了Map操作消耗。新的范例代码如下:
public static final AttributeNamespace ns = AttributeNamespace.createNamespace("mynamespace");
public static final AttributeKey key = new AttributeKey(ns, "mykey");
DefaultAttributeMap attributeMap = new DefaultAttributeMap(ns, 8);
Object value = attributeMap.get(key);工作机制简单说明如下:
key类型由String改为自定义的AttributeKey,AttributeKey会在初始化阶段就去AttributeNamespace申请一个固定id
map类型由HashMap改为自定义的DefaultAttributeMap,DefaultAttributeMap 内部使用数组存放数据
操作DefaultAttributeMap直接使用AttributeKey里存放的id作为index访问数组即可,避免了hash计算等一系列操作。核心就是将之前的字符串key和一个固定的id对应起来,作为访问数组的index
对比HashMap和DefaultAttributeMap,性能提升约30%。
HashMap put time(ms) : 262
ArrayMap put time(ms) : 185
HashMap get time(ms) : 184
ArrayMap get time(ms) : 126
在刚刚过去的 2017 年双 11 中,HSF服务治理(HSFOPS)上线了诸多提升应用安全、运维效率的新功能,如:
服务鉴权
单机运维
连接预热
其中,在今年双11中发挥最大价值的,当属 HSF 连接预热功能。
HSF 连接预热功能,可以帮助应用提前建立起和 Providers 之间的连接,从而避免首次调用时因连接建立造成的 rt 损耗。
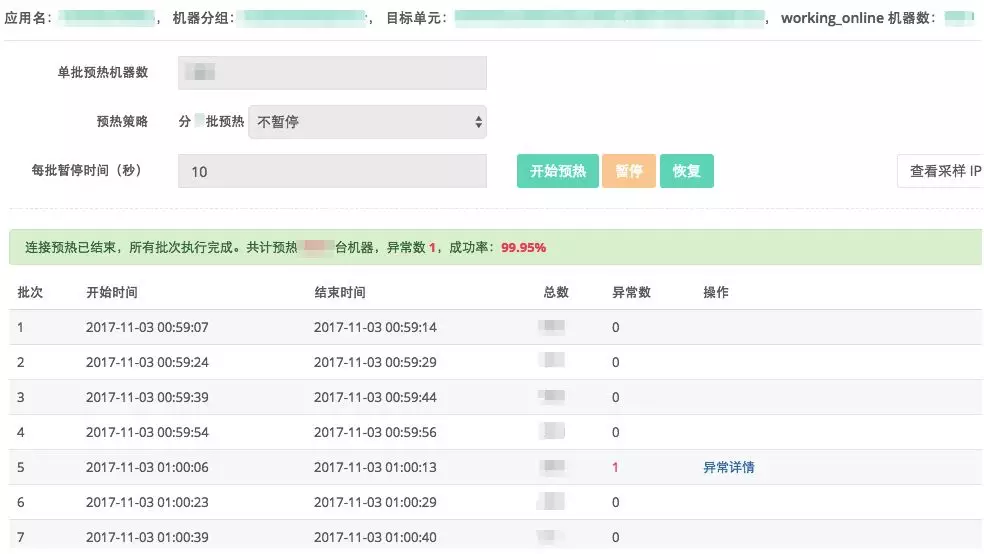
HSF服务治理平台的连接预热功能,支持指定应用、机器分组以及单元环境的预热,并且可以指定预热执行计划,并支持按预热批次暂停、恢复预热。在 2017 双 11 预热完成后,目标应用集合整体连接数增长大于50%,部分应用增长达 40 倍,符合连接预热的预期。
小结
架构升级使HSF能够从容的应对未来的挑战,性能优化让我们在调用上追求极致,运维提升更是将眼光拔高到全局去思考问题,这些改变共同的组成了HSF2.1到HSF2.2的变革,而这次变革不仅仅是稳定的支撑2017年的双十一,而是开启了服务框架下一个十年。








留言评论
暂无留言