
在Aliware Open Source 深圳站的活动上,阿里巴巴高级技术专家许真恩(慕义)发布了Nacos首个开源版本v0.1.0,帮助开发者更简单的构建云原生应用的动态服务发现、配置管理和服务管理平台。本文将为大家探秘阿里巴巴服务注册中心 ConfigServer 的 10 年自研历程。

一、阿里巴巴服务注册中心技术发现路线
阿里巴巴早在2008年就开始了服务化的进程,在那个时候就就已经自研出服务发现解决方案(内部产品名叫ConfigServer)。
当2012年9月1号Eurake放出第一个1.1.2版本的时候,我们把ConfigServer和Eurake进行了深度的对比,希望能够从Eurake找到一些借鉴来解决当时的ConfigServer发展过程中碰到的问题(后面会提到);然而事与愿违,我们已经发现Eureka1.x架构存在比较严重的扩展性和实时性的问题,这些问题ConfigServer当时的版本也有大同小异的存在,于是我们在2012年年底对ConfigServer的架构进行了升级来解决这些问题。
当2015年Eurake社区放出2.0架构升级的声音的时候,我们同样第一时间查看了2.0的目标架构设计,我们惊奇的发现Eurake的这个新架构同2012年底ConfigServer的架构非常相似,当时一方面感慨“英雄所见略同”,另一方也有些失望,因为ConfigServer2012年的架构早已无法满足阿里巴巴内部的发展诉求了。
下面我从头回顾一下,阿里巴巴的ConfigServer的技术发展过程中的几个里程碑事件。
二、2008年,无ConfigServer的时代
借助用硬件负载设备F5提供的VIP功能,服务提供方只提供VIP和域名信息,调用方通过域名方式调用,所有请求和流量都走F5设备。
遇到的问题:
负载不均衡:对于长连接场景,F5不能提供较好的负载均衡能力如服务提供方发布的场景,最后一批发布的机器,基本上不能被分配到流量需要在发布完成后,PE手工去断开所有连接,重新触发连接级别的负载均衡。
流量瓶颈:所有的请求都走F5设备,共享资源,流量很容易会打满网卡,会造成应用之间的相互影响。
单点故障:F5设备故障之后,所有远程调用会被终止,导致大面积瘫痪。
三、2008年,ConfigServer单机版 V1.0
单机版定义和实现了服务发现的关键的模型设计(包括服务发布,服务订阅,健康检查,数据变更主动推送,这个模型至今仍然适用),应用通过内嵌SDK的方式接入实现服务的发布和订阅;这个版本很重要的一个设计决策就是服务数据变更到底是拉还是压的模式,我们从最初就确定必须采用推的模式来保证数据变更时的推送实时性(Eureka1.x的架构采用的是拉的模式)
当时,HSF和通知就是采用单机版的ConfigServer来完成服务的发现和话题的发现。单机版的ConfigServer和HSF,通知配合,采用服务发现的技术,让请求通过端到端的方式流动,避免产生流量瓶颈和单点故障.ConfigServer可以动态的将服务地址推送到客户端,服务调用者可以知道所有提供此服务的机器,每个请求都可以通过随机或者轮询的方式选择服务端,做到请求级别的负载均衡。这个版本已经能很好的解决F5设备不能解决的三个问题。
但是单机版本的问题也非常明显,不具备良好的容灾性。
四、2009年年初,ConfigServer单机版 V1.5
单机版的ConfigServer所面临的问题就是当ConfigServer在发布/升级的时候,如果应用刚好也在发布,这个时候会导致订阅客户端拿不到服务地址的数据,影响服务的调用,所以当时我们在SDK中加入了本地的磁盘缓存的功能,应用在拿到服务端推送的数据的时候,会先写入本地磁盘,然后再更新内存数据。当应用重启的时候,优先从本地磁盘获取服务数据。通过这样的方式解耦了ConfigServer和应用发布的互相依赖,这个方式沿用至今(我很惊讶,Eureka1.x的版本至今仍然没有实现客户端磁盘缓存的功能,难道Eurake集群可以保持100%的SLA吗?)
五、2009年7月,ConfigServer集群版 V2.0
ConfigServer的集群版本跟普通的应用有一些区别:普通的应用通过服务拆分后,已经属于无状态型,本身已经具备良好的可扩展性,单机变集群只是代码多部署几台; ConfigServer是有状态的,内存中的服务信息就是数据状态,如果要支持集群部署,这些数据要不做分片,要不做全量同步;由于分片的方案并没有真正解决数据高可用的问题(分片方案还需要考虑对应的故障转移方案),同时复杂度较高;所以当时我们选择了单机存储全量服务数据全量的方案为了简化数据同步的逻辑,服务端使用客户端模式同步:服务端收到客户端请求后,通过客户端的方式将此请求转发给集群中的其他的ConfigServer,做到同步的效果,每一台ConfigServer都有全量的服务数据。
这个架构同Eureka1.x的架构惊人的相似,所以很明显的Eureka1.x存在的问题我们也存在,当时的缓解的办法是我们的ConfigServer集群全部采用高配物理来部署。
六、2010年年底,ConfigServer单机版 V2.5
基于客户端模式在集群间同步服务数据的方案渐渐无以为继了,特别是每次应用在发布的时候产生了大量的服务发布和数据推送,服务器的网卡经常被打满,同时cmsgc也非常频繁;我们对数据同步的方案进行了升级,去除了基于客户端的同步模式,采用了批量的基于长连接级别的数据同步+周期性的续订的方案来保证数据的一致性(这个同步方案当时还申请了国家专利);这个版本还对CPU和内存做了重点优化,包括同步任务的合并,推送任务的合并,推送数据的压缩,优化数据结构等。
这个版本是ConfigServer历史上一个比较稳定的里程碑版本。
但是随着2009年天猫独创的双十一大促活动横空出世,服务数量剧增,发应用布时候ConfigServer集群又开始了大面积的抖动,还是体现在内存和网卡的吃紧,甚至渐渐到了fullgc的边缘;为了提高数据推送能力,需要对集群进行扩容,但是扩容的同时又会导致每台服务器的写能力下降,我们的架构到了“按下葫芦浮起瓢”的瓶颈。
七、2012年底,ConfigServer集群版 V3.0
在2011年双十一之前我们完成了V3架构的落地,类似Eureka2.0所设计的读写分离的方案,我们把ConfigServer集群拆分成会议和数据两个集群,客户端分片的把服务数据注册到会话集群中,会话集群会把数据异步的写到数据集群,数据集群完成服务数据的聚合后,把压缩好的服务数据推送到会话层缓存下来,客户端可以直接从会话层订阅到所需要的服务数据;这个分层架构中,会话是分片存储部分的服务数据的(我们设计了故障切换方案),数据存储的是全量服务数据(天生具备故障转移能力)。
数据集群相对比较稳定,不需要经常扩容;会话集群可以根据数据推送的需求很方便的扩容(这个思路和Eureka2.0所描述的思路是一致的);会话的扩容不会给数据集群带来压力的增加.session集群我们采用低配的虚拟机即可满足需求,数据由于存储是全量的数据我们仍然采用了相对高配的物理机(但是同V2.5相比,对物理机的性能要求已经答复下降)
这个版本也是ConfigServer历史上一个划时代的稳定的大版本。
八、2014年,ConfigServer集群版 V3.5
2013年,阿里巴巴开始落地了异地多活方案,从一个IDC渐渐往多个IDC跨越,随之而来的对流量的精细化管控要求越来越高(比如服务的同机房调用,服务流量的调拨以支持灰度能力等),基于这个背景ConfigServer引入了服务元数据的概念,支持对服务和IP进行元数据的打标来满足各种各样的服务分组诉求。
九、2017年,ConfigServer集群版 V4.0
V3版本可见的一个架构的问题就是数据集群是存储全量的服务数据的,这个随着服务数的与日俱增一定会走到升级物理机配置也无法解决问题的情况(我们当时已经在生产使用了G1的垃圾回收算法),所以我们继续对架构进行升级,基于V3的架构进行升级其实并不复杂,会话层的设计保持不变,我们把数据进行分片,每一个分片同样按照集群的方式部署以支持故障转移的能力。
十、Nacos 是 ConfigServer 的开源实现
作为同属于AP类型的注册中心,Eurake和ConfigServer发展过程中所面临的诸多问题有很大的相似性,但是阿里巴巴这些年业务的跨越式发展,每年翻番的服务规模,不断的给ConfigServer的技术架构演进带来更高的要求和挑战,我们有更多的机会在生成环境发现和解决一个个问题的过程中,实现架构的一代代升级。我们正在计划通过开源的手段把我们这些年在生成环境下的实践通过Nacos 产品贡献给社区,一方面能够助力和满足同行们在微服务落地过程当中对工业级注册中心的诉求,另一方面也系统通过社区及生态的协同发展给ConfigServer带来更多的可能性。
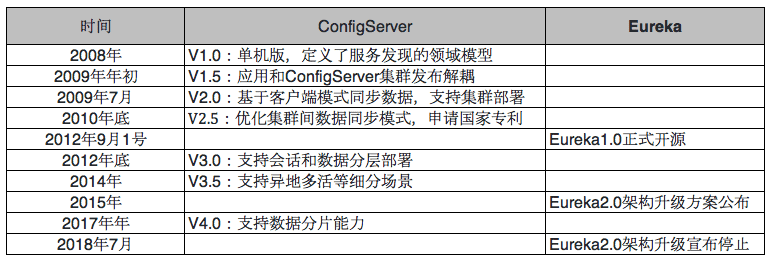 发展历程:ConfigServer vs Eureka
发展历程:ConfigServer vs Eureka
我们看不透未来,却仍将与同行们一起上下求索,砥砺前行。








留言评论
暂无留言